

近年傾向スコアを使った解析を行った医学研究が数多く報告されるようになりました。
傾向スコアは解析がしやすい一方で、解析方法ごとに特徴や注意すべき点があります。
この記事では傾向スコアを使った解析3種類とその特徴をご紹介します!
目次
傾向スコアとは?

傾向スコアとは「ある患者背景を有する症例が治療を受ける確率」です。
傾向スコアは特定の患者背景とどの治療を受けたかのデータによって算出されます。
例えば治療Aを受ける人に男性が多い場合、
治療Aを受ける確率は男性:50%以上、女性:50%未満というように計算されます。
傾向スコアの特徴は複数の背景因子を一つの傾向スコアという指標にまとめることができる点で、
この一つの指標にまとめることができるのが傾向スコアの強みなのです!
例えば、多変量解析を行う際には説明変数が多すぎると変な結果が出てくる、ということがあります。
しかし、傾向スコアを使うと複数の説明変数を傾向スコアの一つにまとめられるので、
解析が安定し、説明変数が多くなってもしっかりとした結果が出てきます!
また、2つの群の患者背景を揃えたいとき、一つ一つの患者背景をそろえることは大変ですし、
そもそも同じ患者背景の症例がいないという場合があります。
このときも傾向スコアが近い症例で揃えることで、すべての患者背景が同じ症例がいない場合でも
平均的に患者背景を揃えることができます。
このように傾向スコアは複数の患者背景や交絡を調整する上で強力な方法なのです!
傾向スコアの算出方法

傾向スコアはロジスティック回帰モデルを使って推定します。
方法はすごくシンプルで説明変数に調整したい因子、結果変数に治療群の情報を入れるだけです!
例えば、性別と年齢を調整したい場合、結果変数に「治療群」、説明変数に「性別+年齢」を
入れることで、それぞれの係数が計算されます。
この係数を使って治療群に割りつけられる確率を計算します。
傾向スコアは以下の方法の方法で求めます。

もし、傾向スコアを計算したい症例の「性別が男性」で「年齢が50歳」の場合には、
計算式にそれらを代入して計算します。
上の式の場合は、「性別が男性」で「年齢が50歳」の症例の傾向スコアは0.614で、
「61.4%で治療群に割り付けられる」という解釈になります。
傾向スコアの算出に使用する因子の選び方

傾向スコアを算出する上で一番キモになるのがどの患者背景を調整するか?ということです。
推奨したい方法は「過去の論文で交絡因子として報告されているかどうか」で判断する方法です!
交絡因子とは本来見たい効果や因果関係をゆがめてしまう因子のことで、
最優先で調整すべき因子になります。
例えば「飲酒の頻度と肺がんに関連するか」を調べると、
「飲酒の頻度が高いほど肺がんを発症しやすい」という結果が出てくることがあります。
実はこの原因には交絡として「喫煙」が関わっています。
「飲酒の頻度が高いほど肺がんを発症しやすい」という結果になったのは、
肺がん発症の強いリスク因子である喫煙が、飲酒する頻度が高い集団で多く
飲酒と喫煙の見かけ上の関連が生じた、ということになります。
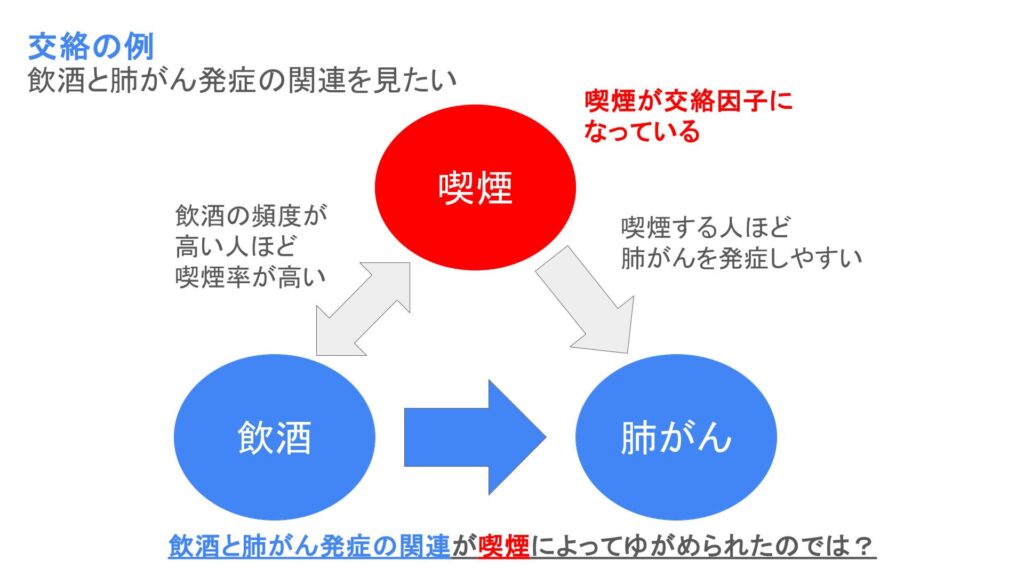
そのため、患者背景を揃えて真の治療効果を見たい場合には、
最優先で交絡因子を調整する必要がある、ということになります。
では多くの研究で使われている
「患者背景の検定を行ってp値が0.05未満で差があった患者背景を調整する」
という方法はどうでしょうか?
この方法はシンプルでコンセプトも理解しやすい方法ではあるのですが、
個人的にはあまりいい方法とは言えません。
というのも、検定のp値は症例数に依存しますし本来調整すべき交絡因子を見落とす可能性もあります。
そのため、傾向スコアの算出には既報で交絡因子と報告された因子を使用しましょう!
傾向スコアを使った解析

ここでは傾向スコアを使った解析を3種類紹介します!
それぞれの使い方や特徴を見ていきましょう。
多変量解析
傾向スコアを使った多変量解析は説明変数に傾向スコアを加えた解析のことです。
この解析の良いところは交絡因子や調整すべき因子が多い場合、
効果の推定がうまくいかないことがありますが、
傾向スコアという一つの因子にまとめているため、
交絡を調整しながら安定した効果の推定が可能になります。
逆確率重み付け(IPTW)
逆確率重みづけは患者の情報を傾向スコアの逆数で膨らませて解析を行う方法です。
傾向スコアの逆数での重み付け方法は群間で異なり、
例えば治療Aと治療Bの治療効果を比較するときには、
治療Aでは1/傾向スコア、治療Bでは1/(1-傾向スコア)で重みをつけます。
こうすることで、通常は無視されてしまうような傾向スコアが小さい=特徴的なデータを
大きく見積もることができ、全体の患者背景を整えることができます!
ただし、傾向スコアが極端に小さいまたは大きい症例がいる場合は、
その症例の情報が過剰に評価されてしまうことには注意が必要です。
傾向スコアマッチング
傾向スコアマッチングは群間で傾向スコアが近い症例をマッチングさせる方法です。
傾向スコアを使ってマッチングさせることで、患者背景が平均的に同じになり、
交絡の影響を除去することができます。
効果を直接的に推定する多変量解析や逆確率重みづけと比べて、
傾向スコアマッチングは解析対象集団の絞り込みが目的です。
そのため、マッチング後に解析を行う必要があります。
傾向スコアマッチングを行った後の解析では
マッチングしていることを考慮した解析を行う必要があります。
よく使われるのは「対応のある解析」です。
「対応のある解析」は同一症例の登録時のスコアと1年後のスコアのように、
関連のあるデータを扱う解析方法です。
傾向スコアマッチングでも、マッチングペア間では傾向スコアが近いという関連があるため、
「対応のある解析」が使われます。
どの解析を報告すべき?

ここまで3種類の解析方法を紹介しました。ではどの解析を使うのが一番よいのでしょうか?
実はどの解析にも特徴があり、強み弱みがあります。
そのため、「どのような状況でも、この解析を行えばOK」という方法はありません。
というのも、傾向スコアが使用される研究は後ろ向きに行われることが多く、
解析計画が事前に定められることは多くありません。
そのような場合、解析手法の選択によって結果の解釈が変わることがあります。
例えば、同じ結果でも検定の選択によって算出されるp値が変わってきます。
検定Aと検定Bの検定のp値がそれぞれ5%未満と5%以上であった場合、
これは「差がある」と結論付けてよいでしょうか?
また研究者なら「差がある」方を報告したくなるのではないでしょうか?
このような都合のいい報告を避けるためにも、
後ろ向き研究では複数の方法で解析を行って、すべての結果を報告すべきです!
また複数の解析結果が同様の傾向である場合、「結果の頑健性」を示すことにもなり、
研究の質の担保にもなります。
傾向スコアを使った解析でも同様に
3種の解析を行って、すべての結果を示し、結果の頑健性を担保するようにしましょう!
まとめ

今回は傾向スコアとは何か?と傾向スコアを使った解析方法について解説しました!
傾向スコア解析は交絡を調整する上で優れた方法ですが、様々な注意点があるので、今回の記事でご理解いただけたならうれしいです!
この記事のまとめ
- 傾向スコアは「ある患者背景を有する症例が治療に割り付けられる確率」のこと
- 傾向スコアを使った解析の代表的な方法は多変量解析、IPTW、マッチング
- 全ての解析方法を行って、結果の頑健性を示すことが大切!


コメント