

医学研究ではエビデンスレベルの高い研究としてランダム化比較試験が行われます。ランダム化比較試験はエビデンスレベルの高い研究ですが、実施する際には注意することがあります!
この記事ではなぜランダム化が必要か、何に注意すべきなのか、またどんな方法があるかを解説します!
要約
- ランダム化は意思が入らずに治療を割り付ける方法
- ランダム化を行うことで未知の交絡因子も含めて患者背景を揃えられる
- 次の割付がわかってしまう予見性に注意!
ランダム化はなぜ必要?
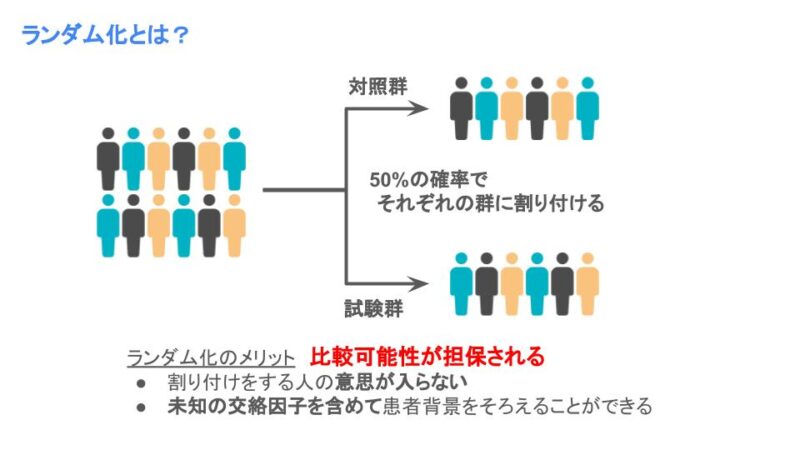
ランダム化とは対照群(プラセボや標準治療)と試験群(新治療)の治療効果を比較するときに、登録された患者を対照群と試験群に確率的に割りつける方法です。例えば対照群と試験群の二群を比較する時には、対照群にも試験群にも50%の確率で割り付けます。
重要な点は「確率的に」の部分で、治療を選ぶときに誰の意思も入らないことが重要です。
というのも、もし割付に意思が入ってしまうと、対照群には予後の悪い患者を、試験群には予後のいい患者を割りつけてしまうような、どちらかの群に有利な割付を行ってしまう可能性があります。そうすると治療効果の差が本当に治療による差なのか、患者の状態による差なのか、分からなくなってしまいます。
また確率的に割りつけることで平均的に患者背景を揃えることができます。この患者背景には治療効果に影響があることが分かっている患者背景(既知の交絡因子)の他、まだ治療効果に影響があるか分かっていない患者背景(未知の交絡因子)も揃えることができます!
そのため、ランダム化を行うことで群間の比較可能性が担保され、ランダム化を行った研究はエビデンスレベルが高い研究とみなされます。
ランダム化で注意すべき点
ではランダム化を行えばオールOKか?というとそうではありません!
ランダム化を行う上では、割付の予見性に注意する必要があります。
割付の予見性とは「次に登録される患者がどちらの群に割りつけられるか予想できること」です。予見性があると、次の治療が対照群に割り付けられそうであれば予後の悪い患者を、試験群に割り付けられそうであれば予後の良い患者を登録する、という操作が可能になります。
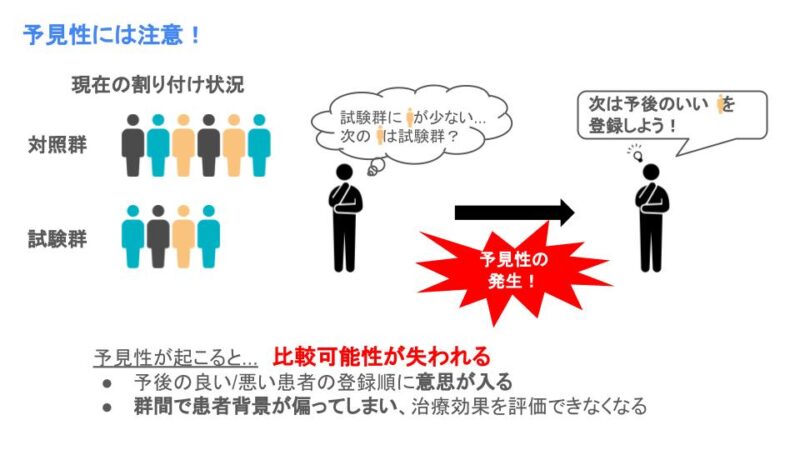
よく言われるような各群に等確率で割付られる方法ではこのようなことは起こりませんが、後述するブロックランダム化などのランダム化割付方法の場合は割付の予見性が問題視されます。
ランダム化の方法
ここでは代表的なランダム化の方法(単純ランダム化、ブロックランダム化、層別ランダム化)について解説します!
単純ランダム化
単純ランダム化は最もシンプルな方法で、全ての治療群に等確率で割りつける方法です。例えばK個の治療群がある場合は、各治療に1/Kの確率で割りつけます。
単純ランダム化の疑問としてよく「対照群と試験群の症例数が違う」ということを聞かれます。これは確率的に割りつけているために起こっている現象なので大きな偏りがない場合には問題ありません!
例えば、対照群と試験群の二群に割り付ける場合にはそれぞれの50%の確率で割りつけることになります。これはコインの表と裏を使って割り付けているのと同義です。コインの表裏で考えると、コインを10回投げたときに表と裏が常に5回ずつ出るでしょうか?
必ず4回や6回とばらつくことがあります。
これと同じように単純ランダム化では常に対照群と試験群の症例数が同じにはならないのです!
ブロックランダム化
単純ランダム化では治療群の症例数が同じにならない、ということを説明しました。極端には対照群0例、試験群10例のようにどちらかの群に大きく偏る可能性があります。
これを回避するために使用されるのがブロックランダム化です。ブロックランダム化はブロックと呼ばれる割り付けの順番を先に決めておいて、それに従って割り付けて順番に割り付ける方法です。
例えば、対照群と試験群の二群を比較する研究では、2名が登録されるごとに、対照群に割り付けたら次は試験群に、試験群に割り付けたら対照群に投与する、というように割り付けます。
ただ2例ごとに投与を決めると次の割り付けが分かってしまうので、4例や6例など十分な大きさで、治療群数の倍数で割り付けを決めることが一般的です。この4例や6例のことをブロックサイズ、割り付け順のひとまとまりをブロックと呼ぶので、この方法はブロックランダム化と呼ばれます!
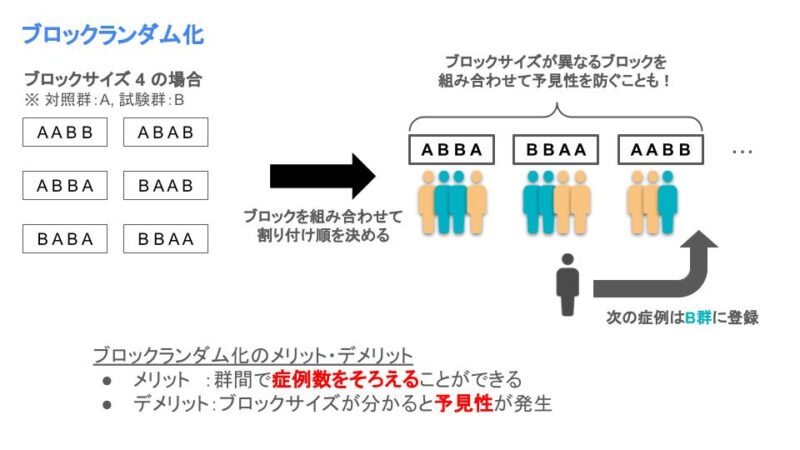
治療Aと治療Bに患者を割り付ける研究を考えてみましょう。ブロックサイズを4としたとき、割り付けのブロックとしては(A,A,B,B)、(A,B,A,B)、(A,B,B,A)、(B,A,A,B)、(B,A,B,A)、(B,B,A,A)の6種類が考えられます。ブロックランダム化ではこの6種類を組み合わせて割り付け順を決めていきます。こうすることで両群の症例数をそろえることができます!
層別ランダム化
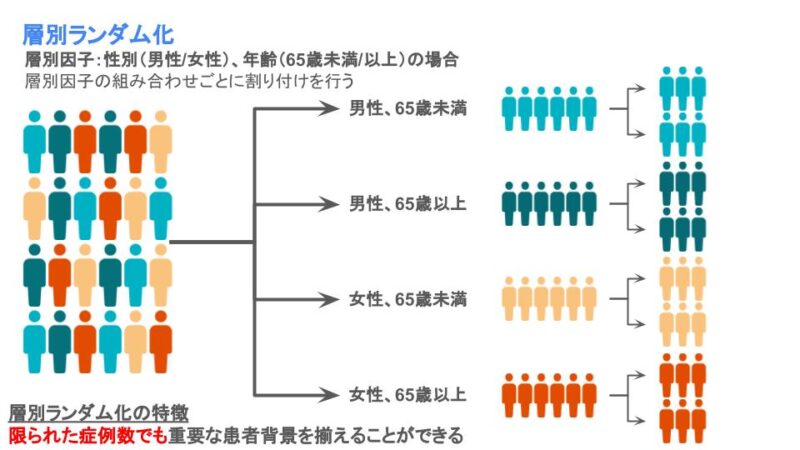
層別ランダム化は偏ってほしくない患者背景を層として、層ごとに治療の割り付けを行う方法です。この層にする患者背景のことは層別因子と呼ばれます。
例えば、性別と年齢(65歳未満/以上)を層別因子とした場合は(男性、65歳未満)、(男性、65歳以上)、(女性、65歳未満)、(女性、65歳以上)の層に分けて、層ごとに治療に割り当てていきます。こうすることで、治療群間で性別と年齢の偏りを減らすことができます。
「ランダム化は平均的に患者背景がそろうから、こんなことはしなくてもいいのでは?」と思われた方もいるかもしれません。(鋭いですねー笑)
この「平均的に患者背景がそろう」は「症例数が無限にいる場合は理論的にはそろう」ということであり、逆に言えば「症例数が限られている多くの臨床試験では患者背景が偏る可能性がある」ということになります。
そのため、交絡因子になりえる重要な患者背景については群間で分布をそろえたい、という意図で層別ランダム化が使われています。
層別ランダム化の注意点として層別因子の選び方があります。多くの場合、層別因子は過去の研究から交絡因子として報告されている因子が選ばれます。というのも交絡因子が群間で偏ってしまうと効果の差なのか、治療による差なのか分からなくなってしまいます。
また層別因子の個数にも注意する必要があります。層別因子が多すぎると層の個数が多くなり、各層に含まれる症例数が少なくなってしまいます。そうなることで各層でのランダム化がうまく作用しなくなることになり、結局群間で患者背景が偏ってしまうことになりえます。
そのため、層別因子は過去の報告から交絡因子から治療効果に強い影響を与える順に、症例数に合わせて個数を調整するようにしましょう!
まとめ
今回はランダム化がなぜ必要なのか?ランダム化をするときに注意すべき予見性について解説しました!
ランダム化比較試験がエビデンスレベルが高い研究であるのは間違いありませんが、特に予見性は見落とされがちで、試験の結果に大きな影響を与えるので注意しましょう!


コメント